生成AIによるビジネス文書の情報活用(RAG)に潜むデータプライバシーリスク

はじめに
業務改善や生産性の向上、ひいては企業の競争力を高めるためにビジネスで生成AIの活用準備を各社が進めています。
中でも、企業内の知識ベースから大規模言語モデルLLMに回答を生成させるAIフレームワーク「RAG」が注目されていますが、RAG活用の為には、データプライバシーの観点でいくつかクリアしなければならない点があります。
トラステッドデータをソースとする生成AI活用が必要
自社のビジネスにおいて、すでに生成AIを活用している企業はまだまだ少なく、多くはChatGPTやオープンソースLLMなどを通して、インターネット上の情報収集や汎用的回答の生成にテスト的に使用しているというケースがほとんどでしょう。ビジネスにおける生成AI活用の第一歩ではありますが、回答の正確性に懸念を感じたことはないでしょうか?不特定多数がアクセスするインターネット上の情報には誤ったものも含まれるため、それらをデータソースとしている生成AIは誤った回答を返してしまうことがあります。また、企業内の情報はトレーニングされていないため、そもそも回答を得ることができません。
生成AIは確率分布に基づくテクノロジーなので、どれだけ技術が進んでも正確性が100%保証されることはありませんが精度を高める取り組みは必要でしょう。生成AIの精度を向上させるには、トラステッドデータ(信頼できるデータ)をデータソースとして活用することが必要不可欠です。
企業にとってのトラステッドデータは、当然ながら自社が保有する大量のデータに基づきます。企業が保有するデータの中で、システムなどデータストレージ内に格納されている構造化データと呼ばれるものは僅か20%ほどに過ぎず、約80パーセントは、見積書や請求書、図面や技術文書、契約書など、PDFやメールなど紙ベースの非構造化データと呼ばれるデータだと言われています。RAG活用が期待されるのは主に非構造化データの部分であり、大量にあるこれらデータをAI活用できれば、人間が判断するための材料として精度やスピード感が高まることで、企業競争力の向上に繋がるでしょう。
トラステッドデータとなるドキュメントの一元管理がRAG実現への第一歩
実際に「RAG」をビジネス活用可能なのでしょぅか?RAG(Retrieval-Augmented Generation)とは、企業内情報など外部の知識ベースから大規模言語モデルLLMに回答を生成させるAIフレームワークのことです。社内データを生成AIのデータソースとして参照させることで、自社固有の回答を生成することができます。トレーニングによって学習した内容を要約する能力や、トラステッドデータやインターネット上のデータソースから関連性の高い文書やテキストを検索する能力も高まるため、最新情報に沿って、詳細かつ正確性の高い回答の生成を実現することができます。
OpenTextでは実際にRAGを活用しています。160ファイル以上におよぶ社内用のマニュアルやリリースノートなどを、独自のトラステッドとしてデータ生成AIのデータソースとして活用しています。問い合わせ時に必要な情報を網羅的に検索しお客様への回答精度を高めたり、人材育成においては社員が自身に必要なドキュメントを検索するために活用しています。他にも途中からPMを任されたプロジェクトに関する大量のドキュメントを引き継いだ時の情報キャッチアップや、引き継いだ業務の前任者がすでに退職しているケースでのフォローなどにも活用できるでしょう。社員の判断や業務をサポートするためのツールとして活用することで、精度や効率性が劇的に改善しています。
RAGを実装するためには、まずトラステッドデータとなるコンテンツの管理を徹底することが必要です。
社内の大量のビジネス文書を一元化し、信頼できる「コンテンツ管理基盤」をつくり、その基盤と生成AIが連携することで、すべての従業員が自社のビジネス文書全体をデータソースとした生成AIの活用が可能になります。
情報漏洩への懸念…RAG実装は複雑で難しい面も
RAGの実装にあたり、生成AIに社内のデータをデータソースとして提供するうえで、データの適切な管理は重要なテーマとなります。適切に管理できていなければ情報漏洩や、回答精度が上がらず思ったように活用が進まない…といった事態に陥る可能性があります。
生成AIが情報を漏洩しないよう、データごとの権限を継承したまま情報だけ活用する
フォルダで管理されていた際にはアクセス権限を利用者ごとに行っていたが、そのフォルダを含むデータソースをAIが活用する際に、本来閲覧権限のない社員にまで情報を利用者に伝えて情報漏洩に繋がってしまうかもしれません。ある従業員が知り得てはならない社内の機密情報などを、AIがうっかり回答に織り込んでしまう状況に陥らないようAI活用においても権限の範囲を逸脱しないきめ細かな権限管理を行う必要があります。
自社データを学習した生成AIを他社が使用できないようにする
また、生成AIに自社の情報を学習させることに問題はないのでしょうか?データは企業が保有する貴重な財産です。企業が保有するデータをもとに訓練された生成AIを、もし競合他社が活用してしまったら…? RAG活用においては、社外に自社データが漏れさせないよう、データプライバシーに配慮したデータ管理を徹底しなければなりません。
生成AIをすぐにビジネス活用できる「Content Aviator」
RAGの実装に際しては、これらの点をクリアした状態で設計、実装を行う必要があるため、要件が非常に複雑になりがちです。
OpenTextでは、これらの問題をクリアしながら、生成AIをすぐに活用していただけるソリューションを提供していますSaaS版エンタープライズ・コンテンツマネジメントシステム(ECM)である「OpenText Core Content」は、検索、通知、ビューワ、バージョン管理、属性情報管理、期限管理、レコードマネジメントなど文書管理に必要な機能を保有しているだけではなく、文書管理に必要なすべての機能をリーズナブルかつスピーディに導入することが可能なクラウドサービスです。会話型の生成AIオプション「Content Aviator」と組みあわせることで、Core Contentに格納されているドキュメントをデータソースとして、すぐに、自社データを活用した生成AI機能を活用できるようになります。
特徴① 自社以外のトレーニングは使われない
「Content Aviator」では、LLMとして「Vertex AI」を利用しています。
自社以外のトレーニングには使わない設定になっているため、社内保有するデータに基づいて訓練された生成AIが他社で使用されることはありません。
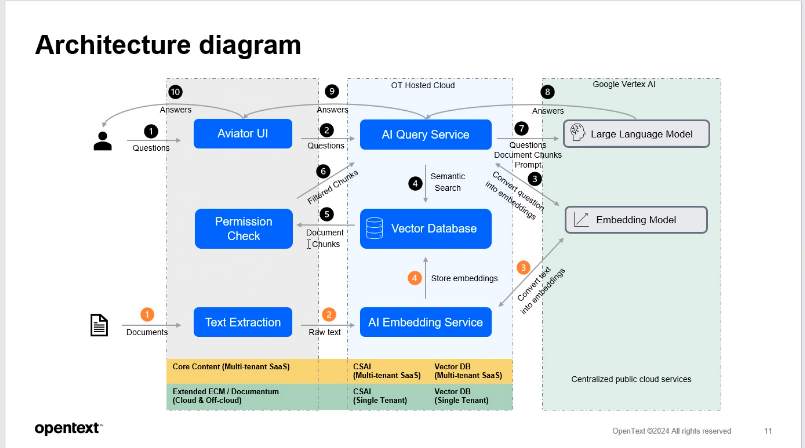
特徴② ドキュメントごとの権限を引き継いだままデータをチャンクに分解し計算する
生成AIがデータを要約する際に、もともとのファイルごとのアクセス権限を引き継いだまま、ユーザーが閲覧可能なドキュメントに記載されている要素だけをピックアップするなど、OpenText独自の高度な技術により安全性を実現しています。Core Contentにアップされたドキュメントから、Content Aviatorは文章を抜き出し、“塊”を意味するチャンクごとに分割を行います。生成AIはチャンクごとに類似関連性を計算しますが、その際にも元のドキュメントに設定されていた閲覧権限をチャンクごとに保持しています。
回答する前のパーミッションチェックによって、抽出されたチャンク1つ1つに対して閲覧権限のあるユーザーなのかフィルタリングを行ったうえで、閲覧可能な情報だけに基づいた回答を生成します。きめの細かい権限管理はCore Contentによって徹底した権限管理が行われているからこそ実現できていいるのです。
AI活用の適用範囲の拡大と共に、データプライバシーの両方を実現するハードルは今後もどんどん高まっていくでしょう。Core Contentはコンテンツを保管するだけでなく、管理の厳格化、従業員の生産性の向上、プロセスの加速、情報に基づいた意思決定をお手伝いするクラウドサービスです。Content Aviatorと組みあわせることで安心・安全かつスピーディに生成AIによる企業の業務効率化、企業競争力の向上を実現します。



